
Understanding neural networks through sparse circuits
OpenAI
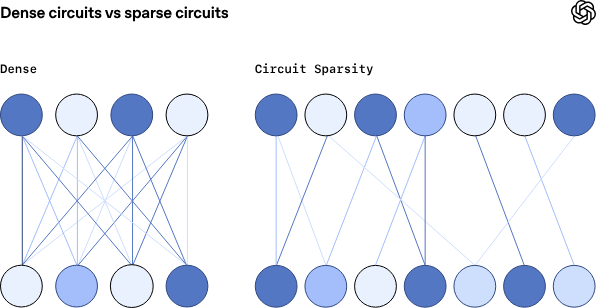
Mechanistic interpretability, which is the focus of this work, seeks to completely reverse engineer a model’s computations. It has so far been less immediately useful, but in principle, could offer a more complete explanation of the model’s behavior. By seeking to explain model behavior at the most granular level, mechanistic interpretability can make fewer assumptions and give us more confidence. But the path from low-level details to explanations of complex behaviors is much longer and more difficult.
Interpretability supports several key goals, for example enabling better oversight and providing early warning signs of unsafe or strategically misaligned behavior. It also complements our other safety efforts, such as scalable oversight, adversarial training, and red-teaming.
Read more | OpenAI